
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- Gradient Boostnig
- 머신러닝
- multivarite method
- LDA
- LGBM
- ensemble learning
- decision tree
- MLE
- 차원 축소
- Machine Learning
- Regression
- 앙상블 학습
- feature extraction
- multivarite data
- ensemble
- 최대사후확률
- 트리분할
- xgboost
- classification
- dimension reduction
- Maximum A Posterior
- 차원축소
- 앙상블
- pca
- Gbm
- ML
- 알고리즘
- LIKELIHOOD
- Gradient boosting machine
- Gradient Boosting
- Today
- Total
코딩하는 눈송이
[머신러닝] LightGBM(LGBM) 본문
LGBM의 탄생 배경
지난 포스팅에서 GBM에 관한 대표적인 알고리즘 XGBoost에 대해서 알아봤다.
- XGBoost란? 기존 Gradient Boosting 방법론을 사용해서 Decision Tree로 학습을 진행하지만, Loss function에 정규화 항을 더해 모델(트리)의 복잡도를 조절해 overfitting을 방지하고 병렬 학습이 가능하게 만드는 등의 최적화 과정이 들어간 Gradient Boosting Machine
이렇듯 Decision Tree를 만드는 과정에서 Gradient Boosting을 활용하는 방법을 Gradient Boosting Decision Tree(GBDT)라 한다.
- GBDT
- Boosting : Boosting 기법을 활용하며 이전 단계에서 학습하지 못한 부분을 집중적으로 학습
- Gradient : 손실함수를 줄이기 위한 방향을 알려주며, 이전 단계에서 학습한 결과를 기반으로 gradient를 계산한 후, 다음 모델의 학습을 진행
- split : 가장 많은 자원과 시간을 소모하는 과정. 이 과정에서의 알고리즘에 따라서 다양한 알고리즘으로 분류된다.(예시 : XGBoost, LightGBM, CatBoost)
여기서 가장 자원을 많이 소모하는 과정은 split 과정이다.
대표적으로 split algorithm은 Pre-Sort Algorithm, Histogram Based Algorithm 이렇게 크게 두 가지를 들 수 있다.
- Split 알고리즘
- Pre-Sort Algorithm
- 특정 속성을 기준으로 데이터를 분할할 시, 속성의 값을 기준으로 데이터를 정렬
- 매 분할마다 수행되므로 데이터셋이 큰 경우는 연산량이 상당한 편
- 이러한 문제를 해결하기 위해 트리 전체에서 한 번만 정렬하고 그 결과를 재활용하는 방식을 채택
- Histogram Based Algorithm
- 연속적인 변수 값을 이산적인 구간(bin)으로 나누고, 이 구간을 사용하여 학습과정 속에서 피쳐 히스토그램을 구성하는 방법
- XGBoost에서는 이를 기반으로 한 HistGradientBoosting 방식을 채택
- Pre-Sort Algorithm
이러한 histogram based algorithm를 사용하는 XGBoost의 경우에도 트리의 split 과정에서 결국 모든 instance와 feature을 scan해야 하는 문제 때문에 큰 데이터셋의 경우 많은 시간과 자원을 소모하게 된다.
그렇다면 크기가 큰 데이터셋의 경우는 무엇을 줄여야 학습하는 시간과 자원을 아낄 수 있을까?
물론 '데이터셋의 크기(instance)'와 '피쳐(feature)의 갯수'를 줄여야 한다는 생각을 할 수 있다.
'데이터셋의 크기(instance)'를 줄이기 위해 가장 쉽게 생각할 수 있는 것은 Down Sampling이다.
이는 데이터 개체의 중요도(Weight)가 설정된 임계값을 넘지 못할 경우 데이터 개체들이 필터링 되는 경우로, AdaBoost의 경우 sample weight가 데이터 개체의 중요도를 알려주는 역할을 수행하여 이를 기준으로 down sampling이 가능하지만, GBDT에는 데이터 개체에 기본 가중치가 존재하지 않아 이러한 down sampling이 불가하다.
'피쳐(feature)의 갯수'를 줄이기 위해 가장 쉽게 생각할 수 있는 것은 weak한 feature을 필터링하는 것이다.
그러나 대용량 데이터셋의 경우, 보통 데이터가 sparse한 경우가 많다.(데이터가 sparse하다는 것은 일부 feature만 값이 채워져 있고 대부분의 feature들에 대해서는 값이 채워지지 않은, 혹은 0인 데이터를 말한다)
Histogram Based Algorithm의 경우에는 feature의 값이 0이든 1이든 각 데이터 개체마다 구간(bin) 값을 추출해야 하기 때문에 0 값을 무시할 수 없게 된다. 그렇기 때문에 이러한 histogram based algorithm의 경우에도 희소 변수를 효과적으로 활용할 방안이 요구된다.
그렇기 때문에 LightGBM은
- '데이터셋의 크기(instance)'를 줄이는 GOSS(Gradient-based One-Sided Sampling)
- '피쳐(feature)의 갯수'를 줄이는 EFB(Exclusive Feature Bundling)
을 이용해 자원 사용과 학습 시간에 대한 XGBoost의 문제점을 보완한다.
1. GOSS(Gradient-based One-Sided Sampling)
GOSS는 LGBM에서 데이터 샘플링 전략을 개선하는 방법이다.
즉, 데이터셋의 크기를 줄이는 알고리즘으로 기본 가정은 instance의 gradient가 클수록 영향력이 크고, 덜 학습된 instance라는 것이다.
- Gradient가 큰 instance의 의미
- Gradient가 크다는 것은 instance를 구성하는 element 값의 변화가 클 경우 손실함수에 변화가 클 것이고, 이는 모델이 민감하게 반응하게 되므로 모델이 충분히 학습치 못한 instance라는 뜻을 가진다. $$ \Delta L(\theta) = \frac{\delta L}{\delta \theta_{i}} \times \Delta \theta_{i} $$
- 그러니, 이러한 instance를 최대한 많이 포함하는 데이터셋을 만드는 것이 주요 컨셉이다.

알고리즘은 위와 같으며, 단계별로 설명하자면 다음과 같다
- 각 instance들의 gradient 계산 및 정렬
- gradient 상위 $a \times 100%$ 만큼의 instance 선택
- 남은 instance들 중 $b \times 100%$만큼을 무작위로 선택하고, 이 instance들에 상수 $\frac{1-a}{b}$를 곱합
- 이 instacne들은 충분히 학습이 되었으나, 데이터셋의 분포를 위해 일부분을 포함시키며$ \frac{1-a}{b}$는 트리 split 과정에서 information gain을 계산할 시 가중치를 곱해주는 역할을 한다
- 선택한 instance들로 GBDT 생성
GBDT를 학습하는 과정에서 얻는 information gain은 아래와 같이 정의된다.

Split 이후 각 leaf에 분류된 데이터들의 분산이 작을수록 더 잘 분류되었다고 볼 수 있으므로, variance gain이라고 부른다.

여기서 왼쪽과 오른쪽으로 split된 sample들의 분산이 낮을수록 variance gain이 커지는 효과가 있다.
$(\sum_{{x_i \in O:x_{ij} \le d}} g_i)^2$과 $(\sum_{{x_i \in O:x_{ij} > d}} g_i)^2$의 차이가 클수록 이는 커지고, 가장 적절한 split point는 variance gain이 최대가 되는 지점이라고 할 수 있다.
축소된 데이터셋에 대한 variance gain $\tilde{V}_j(d)$는 다음과 같이 정의된다.

여기서,
$ A_l = {x_i \in A:x_{ij} \le d}$, $A_r = {x_i \in A:x_{ij} > d}$
$ B_l = {x_i \in B:x_{ij} \le d}$, $B_r = {x_i \in B:x_{ij} > d}$
이며, 집합 B의 gradient에 $\frac{1-a}{b}$를 곱해줌을 알 수 있다.
논문에서는 $\tilde{V}$(축소된 데이터셋의 variance gain)와 $V$(원 데이터셋의 variance gain) 사이에 upper bound가 존재한다고 설명한다.
자세한 과정은 논문 내에서 확인 가능하며, 정리된 수식은 다음과 같다.

위의 정리에서, (1) n이 커질수록 / (2) instance들이 좌우 leaf에 균등하게 분리될수록 approximation error가 작아진다고 설명한다.
(1) n이 커질수록 두번째 항에 해당하는 $2DC_{a,b} \sqrt{\frac{\ln{1/\delta}}{n}}$가 0으로 수렴할 것
(2) split point가 잘 설정되어 있다면 $\max {{\frac{1}{n_l^j(d)}, \frac{1}{n_r^j(d)}}}$ 값이 충분히 작아져 approximation error 값이 유의미하게 작아진다.
결론적으로, GOSS를 이용하여 데이터셋을 축소시키더라도 충분한 성능이 나옴을 위 논문에서는 증명했다.
2. EFB(Exclusive Feature Bundling)
EFB는 데이터셋의 Feature 수를 줄이는 알고리즘이다.
고차원의 데이터가 sparse하다는 가정 하에 상호배타적인 변수들을 하나의 bucket으로 묶어서 feature들의 오류를 줄이는 방식을 말한다.
논문은 상호배타적인 문제를 묶어서 하나의 bundle로 만드는 문제는 NP-hard이기 때문에 Greedy 알고리즘을 이용해야 한다고 주장한다.
- NP 문제란? 쉽게 해결할 수 있는 비결정적인 문제들의 집합이다. 여기서 비결정적이라 함은 여러 가지 풀이 가능성을 고려할 수 있음을 의미한다.
- NP-hard : 모든 NP 문제를 다항 시간 안에 문제 'A'로 환원할 수 있는 문제(다항 시간 내에 해결될 수도, 안될 수도 있는 문제)
- NP-complete : 모든 NP 문제들을 환원시킨 문제가 또 다시 NP 문제가 될 수 있는 경우
- 출처 : https://velog.io/@hysong/%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98-P-NP-%EB%AC%B8%EC%A0%9CP-NP-Problem
[알고리즘] P-NP 문제(P-NP Problem)
P-NP 문제는 P = NP인지 증명해야 하는 문제이다. P 집합은 NP 집합의 부분집합이므로, 모든 NP 문제가 P 문제인지 아닌지를 증명하면 된다. 이는 컴퓨터과학 분야의 대표적인 미해결 문제이면서 밀
velog.io
아무튼 논문에서 사용하는 이론을 정리하자면 다음과 같다.

- 데이터셋의 각 변수들을 그래프의 vertex로 치환
- 상호배타적이지 않은 변수들을 Edge로 연결
- 이 그래프 색칠 문제에서 필요한 최소한의 색깔 수는 bundle의 갯수에 대응됨
최소한의 bundle을 찾는 문제는 NP-hard이기 때문에 다항시간 내 문제를 푸는 알고리즘은 없으며, 이렇기 때문에 Greedy 알고리즘을 통해 이 문제에 대한 근사 해답을 찾는 것이다.
변수의 경우, 100% 상호 배타적인 변수들은 적을 것이므로 conflict(상호 배타적이지 않은 instance 갯수)를 허용하는 조건을 추가한다. 이를 random polluting이라고 하며 이를 적용했을 때 upper bound가 있음을 논문에서 역시 증명한다.
(하지만 필자는 conflict에 대한 개념도 사실 잘 이해하지 못했다)
Random polluting은 파라미터 $\gamma$의 형태로 제시되며 이는 전체 데이터셋의 $\gamma \times 100%$ 미만에 해당하는 conflict만 허용하겠다는 뜻이다.
EFB 내 Greedy Bundling 알고리즘은 다음과 같다.
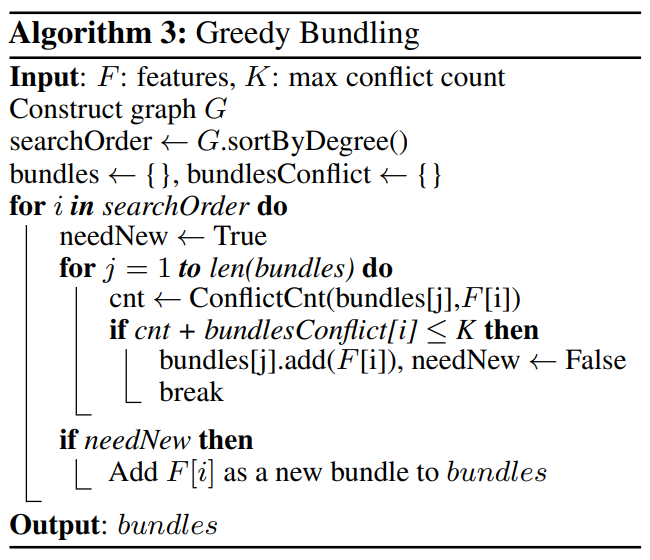
- 변수들의 상호배타여부를 고려해 그래프 G를 생성
- 서로 상호배타적인 변수들은 Edge로 연결되어 있지 않고
- 각 Edge의 weight는 Edge와 연결된 두 Vertex 사이의 conflict
- 그래프의 각 Vertex들의 Degree를 계산하고, Degree 크기에 따라 정렬
- Vertex의 Degree는 해당 Vertex에 연결된 모든 Edge들의 Weight의 합
- Bundle을 만들고 Degree가 큰 변수 순서대로, 나머지 변수들의 conflict 계산
- conflict의 합이 전체 데이터셋 갯수 $\times \gamma \times 100%$미만이 될 때까지 Bundle에 추가
- Bundle의 conflict 합이 기준을 넘어서면 새로운 Bundle을 만들고, 모든 변수를 다 쓸 때까지 3,4 과정을 반복
위는 변수들을 상호 배타적인 Bundle로 구성하는 방법이었다.
아래는 Bundle로 구성된 변수들을 하나의 변수로 만드는 과정(merging)이 필요하다.
다음과 같은 알고리즘으로 merging이 진행된다.

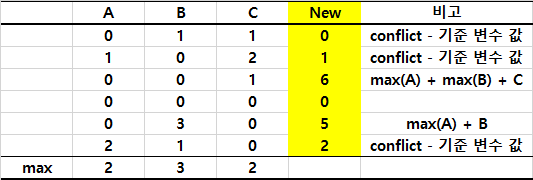
- Bundle 내에서 기준 변수 설정
- 모든 instance에 대해 conflict한 경우는 기준 변수 값 그대로 가져감
- 모든 instance에 대해 conflict가 아닌 상호배타적인 경우 기준 변수의 최댓값 + 다른 변수 값 취합
변수들에 해당하는 값들이 서로 겹치지 않게 기준 변수의 최댓값에 해당 변수의 값을 더해서 새로운 변수 값으로 취하는 것이고, 아래 예시는 Bundle에 3개의 변수가 있을 때의 예시이다.
LGBM 정리
위에서 소개한 데이터셋 축소 알고리즘(GOSS, RFE) 방식으로 LGBM은 여타 GBM 모델보다 가벼운 모델로써 수행 속도를 큰 폭으로 높일 수 있었다.
또한, 수학적으로 Upper bound가 존재함을 보였고 실험적으로도 데이터셋 축소를 진행하지 않은 경우와 큰 성능 차이가 보이지 않음을 증명해냈다.
다음은 알고리즘의 수행 속도와 성능을 실험적으로 측정한 자료이다.

Table 2에서 볼 수 있듯 수행 속도가 매우 빠름을 알 수 있고, Table 3에서는 성능 또한 좋음을 알 수 있다.
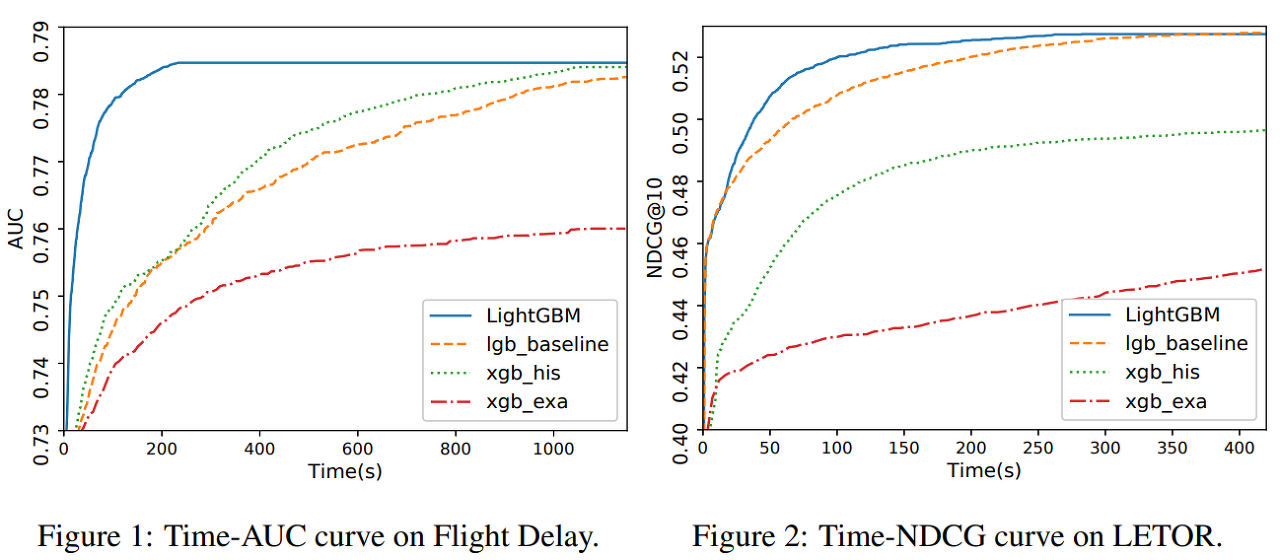
위 그래프에서 LGBM이 학습 시 특정 정확도 수준까지 다른 알고리즘에 비해 빠른 속도로 도달함을 알 수 있다.
References
https://kicarussays.tistory.com/38
[논문리뷰/설명] LightGBM: A Highly efficient Gradient Boosting Decision Tree
LightGBM은 예전에 한 프로젝트에서 정형 데이터 (Table 형태의 데이터) 에 여러 머신러닝 기법들을 적용해보던 중에 발견한 방법이었습니다. CPU만 사용하면서도 GPU를 쓰는 XGBoost보다 훨씬 더 빠르
kicarussays.tistory.com
https://greeksharifa.github.io/machine_learning/2019/12/09/Light-GBM/
Python, Machine & Deep Learning
Python, Machine Learning & Deep Learning
greeksharifa.github.io
https://aldente0630.github.io/data-science/2018/06/29/highly-efficient-gbdt.html
Stats Overflow
A Data Scientist's Tech Blog
aldente0630.github.io
[논문 리뷰] LightGBM: A Highly Efficient Gradient Boosting Decision Tree
참고 온라인 강의 영상 고려대학교 산업경영공학부 강필성 교수님 https://www.youtube.com/watch?v=4C8SUZJPlMY Boosting 시리즈 (Ada-XG-LightGBM-Cat) 중 하나인 LightGBM부터 다루어보도록 하겠습니다! LightGBM이 개
yscho.tistory.com
'머신러닝 > 알고리즘' 카테고리의 다른 글
| [머신러닝] XGBoost (0) | 2023.08.23 |
|---|---|
| [머신러닝] Decison Tree (0) | 2023.07.27 |
| [머신러닝] Gradient Boosting Machine (1) | 2023.07.25 |
| [머신러닝] Random Forest (0) | 2023.07.02 |
| [머신러닝] Ensemble Learning (0) | 2023.07.02 |



