
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- dimension reduction
- decision tree
- Gradient Boostnig
- multivarite data
- Gradient Boosting
- 머신러닝
- Gradient boosting machine
- Maximum A Posterior
- 앙상블
- 트리분할
- ML
- xgboost
- 앙상블 학습
- ensemble
- Regression
- 차원 축소
- MLE
- Machine Learning
- ensemble learning
- Gbm
- 최대사후확률
- 알고리즘
- LGBM
- pca
- 차원축소
- classification
- LDA
- feature extraction
- multivarite method
- LIKELIHOOD
- Today
- Total
코딩하는 눈송이
[머신러닝] Random Forest 본문
Random Forest란?
Random Forest(랜덤 포레스트)는 앙상블 학습의 한 종류로, 의사결정 트리(Decision Tree)를 기반으로 한 모델이다.
Bagging 기법을 활용해서 여러 개의 의사 결정 트리를 생성하고, 그 과정에서 변수를 랜덤으로 선택하는 과정을 추가한다. 그들의 예측 결과를 평균화하여 더 강력하고 안정적인 예측을 수행하는 방법이다. 랜덤 포레스트는 의사 결정 트리의 과적합(overfitting) 문제를 해결하고, 데이터의 다양성을 적극적으로 활용하여 높은 성능을 가지는 특징이 있다.

랜덤 포레스트의 동작 방식은 다음과 같다.
- 데이터 샘플링
- 원본 데이터셋에서 랜덤 복원 샘플링(Bootstrap)을 진행하여 train set을 만든다. 각기 데이터셋의 크기는 같지만 복원 샘플링이라 중복된 샘플을 포함할 수도 있다.
- 의사 결정 트리 구성
- 각 샘플링된 데이터를 사용하여 각각의 의사 결정 트리(Decision Tree)를 학습한다. 이 때의 각 의사 결정 트리는 독립적으로 학습된다.
- 이 때, 각 의사 결정 트리에서는 전체 feature 중, 변수를 랜덤으로 일부 고르는 과정을 거치게 된다.
- 의사 결정 트리는 분류 문제의 경우 엔트로피나 불순도를 최소화하는 방향으로 분할 기준을 설정하며, 회귀 문제의 경우 평균 제곱 오차를 최소화하는 방향으로 분할 기준을 설정한다.
- 예측 수행
- 학습된 의사 결정 트리들을 사용하여 새로운 데이터에 대한 예측을 수행한다. 각 의사 결정 트리는 자체적으로 예측 결과를 내놓는다.
- 앙상블 예측
- 각 의사 결정 트리의 예측 결과를 모아 다수결 투표(voting) 또는 평균화하여 최종 결과를 도출한다. Categorical data의 경우(분류) 다수결 voting이, continuous data의 경우(회귀) 평균을 내는 방식으로 예측 값을 도출한다.
여기서 가장 중요한 컨셉은, 2번 의사 결정 트리 구성 과정에서 데이터의 일부 feature만을 랜덤으로 선택하는 과정이 random forest의 가장 중요한 컨셉을 결정하는 과정이라고 설명할 수 있다.
Random Forest의 무작위성
Feature selection의 무작위성을 얘기할 때 가장 많이 드는 예시가 바로 건강의 위험도 예시이다.
건강의 위험도를 예측하기 위해서는 많은 요소를 고려해야 한다. 성별, 키, 몸무게, 지역, 운동량, 흡연유무, 음주 여부, 혈당, 근육량, 기초 대사량 등등등... 수많은 요소가 필요할 것이다.
이렇게 수많은 요소(Feature)를 기반으로 건강의 위험도(Label)를 예측한다면 분명 오버피팅이 일어날 것이다. 예를 들어 Feature가 30개라고 한다면. 30개의 Feature를 기반으로 하나의 결정 트리를 만든다면 트리의 가지가 많아질 것이고, 이는 오버피팅의 결과를 야기할 것이다.
이러한 오버피팅을 Random Forest는 feature selection의 무작위성 선택을 통해 일반화하고, 그럼으로 overfitting을 극복한다는 컨셉을 띄고 있다.
변수를 랜덤으로 선택하는 과정에서 개별 tree 간의 상관성이 줄어들고, 랜덤 포레스트의 일반화 오류(Generalized Error)가 작아지는 현상이 나타난다.
즉, 개별 tree들의 상관성이 줄어들면 랜덤 포레스트의 예측력이 좋아진다는 뜻이다.
위 그림은 전체 10개의 변수 중 분리할 때마다 2개씩 랜덤하게 변수를 선택하고, 그 중에서 최적 변수와 분리기준을 선택하는 과정이다.
여기서 주의할 것은
변수 후보를 한 번만 랜덤하게 선택해 놓고 그 변수들만 가지고 분리를 하는 것이 아니라는 것이다.
즉, 다음과 같이 변수를 선택하는 것이 아니라는 것이다.
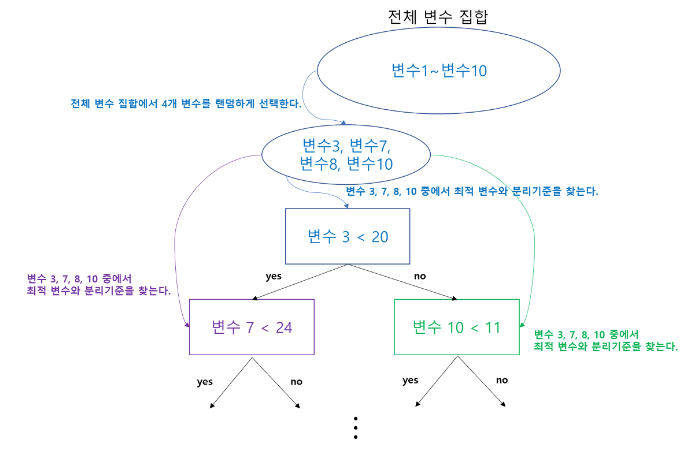
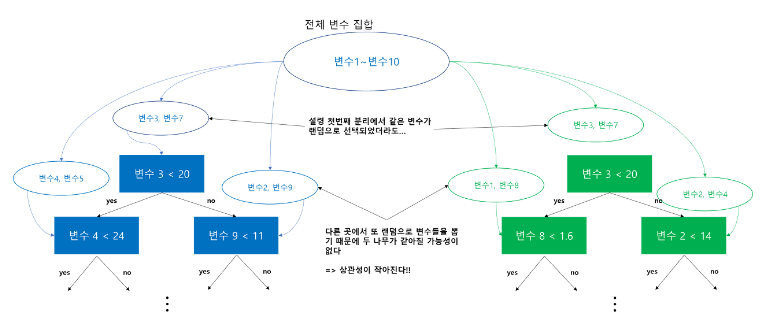
그렇다면 이 과정이 어떻게 개별 tree 사이의 상관성을 줄여주는 것인가?
위에서 설명한 것과 같이 랜덤 포레스트는 tree가 depth가 내려가는 과정에서 분리 때마다 변수를 랜덤하게 선택해서 그 중 최적의 변수와 분리 기준을 선택한다고 했다.
그러니 처음 노드(분리)에서 같은 변수가 선택되었을지 언정 다음 depth로 내려갈 때 분리마다 랜덤으로 변수가 선택되는 과정을 거치기 때문에 다른 변수가 선택될 확률이 굉장히 높아 개별 tree끼리 같아질 가능성이 거의 없어진다.
이는 개별 tree간의 상관성이 작아짐을 의미한다.
Random Forest의 특징
랜덤 포레스트의 장점은 다음과 같다.
- Overfitting 감소 : 랜덤 포레스트는 무작위성의 도입을 통해 의사 결정 트리들을 생성하고 앙상블한다. 이를 통해 과적합(overfitting)이 줄어들고, 일반화 성능이 향상된다.
- 일반화 및 성능 우수 : 다양한 다수의 의사 결정 트리의 결과를 종합하기에 단일 의사 결정 트리보다 더 좋은 성능을 보인다.
- 데이터 scaling 변환 불필요 : Bootstrap의 무작위 추출이나 결정 트리의 비선형 분할로 인해 데이터 scaling이 필요하지 않다.
- 변수 중요도 추정 : random forest에서는 각 feature의 중요도를 추정할 수 있다. 중요도 추정은 모델의 설명력을 향상시키고, 변수의 상대적인 영향력을 파악하는데 도움을 준다.
- 대용량 데이터 처리 : 대용량 데이터 처리에 효과적이며 부트스트랩 샘플링과 병렬 처리를 활용하여 큰 데이터셋에서도 빠른 속도로 학습과 예측이 가능해진다.
랜덤 포레스트의 단점은 다음과 같다.
- 모델 해석의 어려움 : 다수의 의사 결정 트리를 앙상블하는 방식으로 동작하여 모델 자체의 해석은 어려우며 개별 의사 결정 트리의 규칙을 이해하기 어렵고, feature의 중요도만으로는 전체 모델의 동작을 이해하기 어렵다.
- 메모리 사용량 : 다수의 의사 결정 트리를 사용하기에 메모리 사용량이 높을 수 있고, 데이터의 크기가 큰 경우에도 메모리 부담이 있을 수 있다.
- 학습 시간 : 다수의 의사 결정 트리를 학습해야 하기에 학습 시간이 상대적으로 오래 걸릴 수 있다.
- Train Data로 성능 개선 어려움 : Train Data를 추가한다 해도 모델 성능 개선이 어려운 경향이 있다.
랜덤 포레스트를 이용하기에 적합한 데이터는 다음과 같다.
- 다양한 Features : 데이터 셋이 다양하고 많은 feature을 가질 시 성능이 우수하다. Tree 생성 시 각 분리에서 일부의 feature만 선택하여 예측하기 때문에 많은 feature을 가진 데이터셋이 random forest를 적용하기가 좋다.
- Mixed(혼합된) 데이터 : 범주형 feature과 숫자형 feature이 함께 있는 데이터의 경우 성능이 우수하다. One hot encoding이나 label encoding을 통해 변환이 가능하기 때문이다.
- Imbalanced(불균형) 데이터 : 클래스 분포가 고르지 못한 불균형 데이터 셋을 처리하기에 용이하다. 랜덤하게 데이터를 추출하기 때문에 불균형을 해소하는데 도움이 된다.
- Non-linear(비선형) 데이터 : Feature과 target variable 사이에 비선형 관계를 찾아내기에 용이하다. Random Forest는 ensemble 과정을 통해 복잡한 상호 작용을 모델링하고 비선형 의사 결정 경계를 찾아낼 수 있다.
- 대규모 데이터셋 : 광범위한 계산 리소스를 필요로 하지 않으며 알고리즘의 병렬 특성을 이용하여 대량의 데이터를 효율적으로 처리할 수 있다.
- 간단한 팁
- 랜덤 포레스트에서 Bootstrap 샘플 수를 B, 랜덤으로 선택할 변수 갯수를 F, 총 변수 갯수가 p라면
- 경험상 B=10p일 경우 좋은 시작점이 될 수 있다.
- 회귀 문제에서는 F≈p/3이거나 F≈√p를 기본 설정값으로 권장한다.
References
https://wooono.tistory.com/115
[ML] 랜덤 포레스트(Random Forest)란?
의사 결정 트리 (Decision Tree) 먼저, 의사 결정 트리 (decision tree)의 개념부터 다뤄보겠습니다. 의사 결정 트리는, 특정 Feature 에 대한 질문을 기반으로 데이터를 분리하는 방법입니다. 사람들이 일
wooono.tistory.com
https://zephyrus1111.tistory.com/249
24. 랜덤 포레스트(Random Forest)에 대해서 알아보자
이번 포스팅에서는 랜덤 포레스트(Random Forest)에 대해서 알아보고자 한다. 랜덤 포레스트(Random Forest)의 개념, 알고리즘, 여러 고려사항 및 장단점에 대해서 정리해보려고 한다. - 목차 - 1. 랜덤 포
zephyrus1111.tistory.com
'머신러닝 > 알고리즘' 카테고리의 다른 글
| [머신러닝] LightGBM(LGBM) (1) | 2023.10.09 |
|---|---|
| [머신러닝] XGBoost (0) | 2023.08.23 |
| [머신러닝] Decison Tree (0) | 2023.07.27 |
| [머신러닝] Gradient Boosting Machine (1) | 2023.07.25 |
| [머신러닝] Ensemble Learning (0) | 2023.07.02 |



