
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- multivarite data
- Gradient Boosting
- LGBM
- 차원축소
- Gradient Boostnig
- Gbm
- MLE
- LIKELIHOOD
- 앙상블
- Machine Learning
- 알고리즘
- decision tree
- Maximum A Posterior
- 머신러닝
- dimension reduction
- ensemble learning
- feature extraction
- ensemble
- pca
- LDA
- 앙상블 학습
- ML
- classification
- 차원 축소
- Gradient boosting machine
- 트리분할
- Regression
- xgboost
- 최대사후확률
- multivarite method
- Today
- Total
코딩하는 눈송이
[머신러닝] Gradient Boosting Machine 본문
Gradient Boosting이란?
이전 Boosting에 관한 내용을 알아봤다.
Boosting이란, 다수의 weak learner를 이용하며 이전 모델에서 분류 혹은 예측하지 못한 샘플에 가중치를 주어 다음 모델에서 이를 중점적으로 학습하게 하여 하나의 strong learner를 만드는 방법이다.
Boosting 기법 내 다양한 알고리즘이 존재하는데, 오늘 알아볼 알고리즘은 Gradient Boosting이다.
Gradient Boosting이란 Gradient(혹은 잔차(Residual))를 이용하여 이전 모델을 보완하는 기법을 의미한다.
여기서 Residual은 이전 모형에서 적합한 뒤 실제값과의 차이를 의미하며, 이를 다음 모형에 넘겨 학습하게 하고 이를 여러 개의 weak learner를 거치며 하나의 strong learner을 만들게 한다.
(보통 GBM의 weak learner로는 decision tree를 사용하게 되며 이를 사용하는 대표적인 GBM 알고리즘은 XGBoost이다. 다른 알고리즘(SVM, linear regression 등)을 사용할수도 있으나 결정 트리가 유연한 편에 속함)
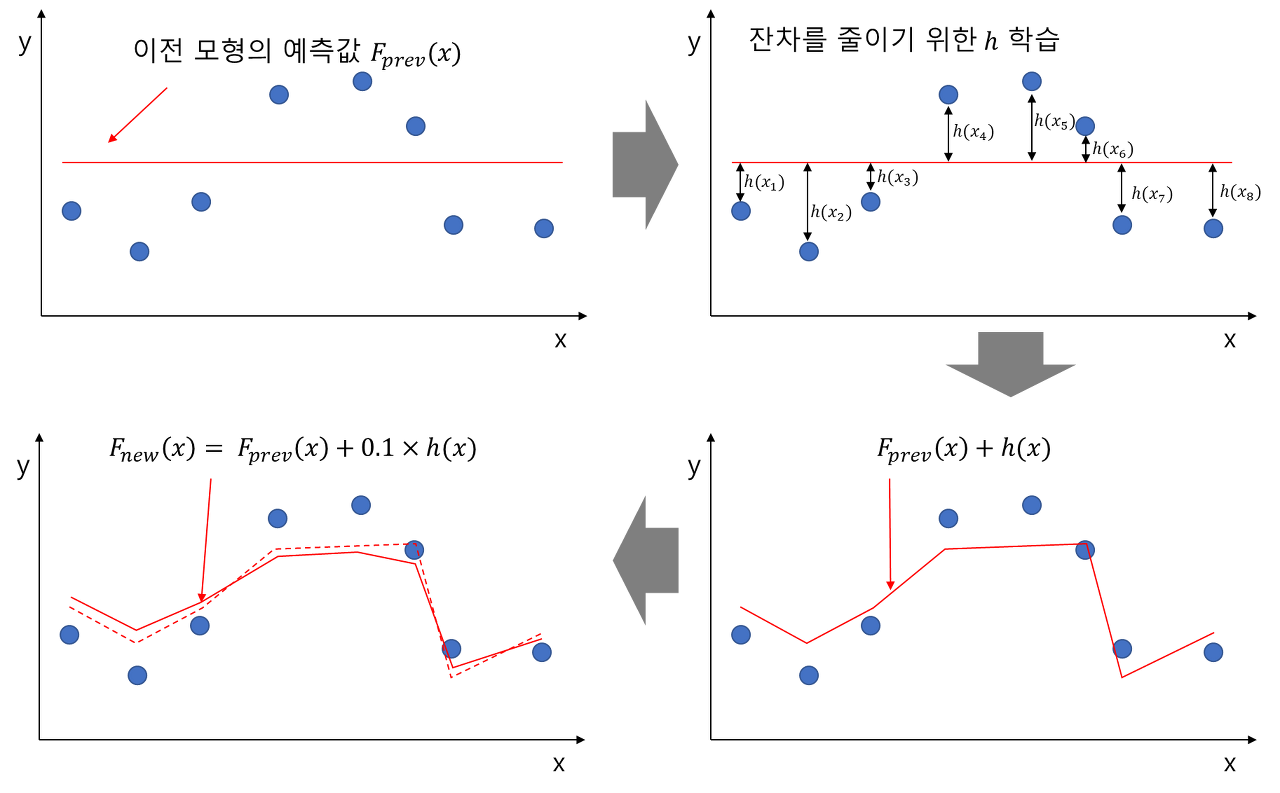
Gradient Boosting은 위 그림과 같은 step을 거치며 진행된다.
- 우선 이전 모형에서 예측한 예측값 $F_{prev}(x)$이 output으로 나오게 되면
- 실제값과의 차이(residual)를 계산하여 다음 모델에서 이를 학습하게 된다.
- 다음 모델은 $h(x)$를 output으로 내놓게 되고 $F_{new}(x) = F_{prev}(x) + lh(x)$로 새로운 예측값이 나온다(l은 learning rate로, 예측값에 곱해주어 과적합을 막아주는 역할을 한다)
- 실제값과의 새로운 residual을 구해 다음 모델의 input으로 사용되게 된다.
여러 개의 weak learner에서 학습한 예측값은 선형 결합을 통해 하나의 output을 만들게 되며 처음 weak learner이 예측한 예측값을 $h_{0}(x)$이라면 다음과 같은 수식으로 표현 가능하다.
$$ F_{m}(x) = h_{0}(x) + lh_{1}(x) + \cdots + lh_{m}(x) $$
Gradient / Residual이란?
그럼 학습을 위해 사용되는 잔차(Residual)는 정확히 무엇이며 이는 Gradient와 무슨 연관이 있는가?
여기서 말하는 Gradient는 Gradient Boosting 알고리즘의 핵심 원리인 Gradient Descent(경사 하강)과 연관이 있다.
- Gradient Descent(경사 하강)이란?
- 최적화 알고리즘 중 하나로, Gradient(기울기) 값을 이용해서 함수의 값이 낮아지는 방향으로 독립 변수 값을 변형시켜 가며 함수의 최솟값을 찾아 가는 iterative한 방법이다.
- 이는 함수가 convex(볼록) 하지 않은 경우 사용이 가능하고 전역해(global minimum)이 아닌 지역해(local minimum)을 찾는 방법이다.

Gradient Boosting에서는 Gradient Descent 즉, 경사하강법을 통해 loss function을 최소화하는 방향으로 학습이 이루어진다.
쉽게 말하자면 다음 모델이 학습하게 되는 이전 모델의 residual은 이전 모델에서의 결과 값을 통한 loss function의 negative gradient와 같다는 말이 된다.
loss function을 squared error로 설정했을 때를 살펴보자
$$ L(y_i, f(x_i)) = \frac{1}{2}(y_i - F(x_i))^2 $$
해당 loss function의 편미분 값은 다음과 같다.
$$ \frac{\partial L(y_i, F(x_i))}{\partial F(x_i)} = \frac{\partial [\frac{1}{2}(y_i - F(x_i))^2]}{\partial F(x_i)} = y_i - F(x_i) $$
결론적으로 Loss function의 Gradient가 실제값($y_{i}$)과 예측값($F(x_{i})$) 사이의 차이인 residual이라는 사실을 알 수 있고, 이를 최소화하는 방향으로 학습하는 것이 residual fitting을 사용하는 GBM의 핵심이라고 할 수 있다.
(이러한 residual fitting model은 Gradient Boosting의 한 일종이며 다른 loss function을 사용하면 다른 gradient 값이 도출되게 된다.)
그렇다면 이런 negative gradient를 사용하는 이유는 무엇일까?
당연하게도 negative gradient가 loss function이 줄어드는 direction이며 해당 모델에 새로운 모델을 fitting해서 이것을 이전 모델과 결합하면, f(x)는 loss function이 줄어드는 방향으로 업데이트되게 된다.
Gradient boosting 알고리즘

초기 input(training set)을 $(x_{i}, y_{i})^{n}_{i=1}$이고 differential loss function이 $L(y,F(x))$, 반복되는 iteration의 수가 $M$일 때,
- Constant value(상수)로 초기 모델을 설정한다$$ F_0(x) = argmin_{\gamma} \sum_{i=1}^nL(y_i, \gamma) $$
- $m = 1 ~ M$에 대해서 다음과 같은 과정을 반복한다(iteration)
- 각 단계에서 pseudo-residual을 구한다 $$r_{im} = -\left [ \frac{\partial L(y_i, F(x_i))}{\partial F(x_i)} \right ]_{F(x)=F_{m-1}(x)} $$
- Pseudo-residual이란? 각 데이터 포인트에 대해, 실제 타겟 값과 GBM이 현재까지 예측한 값 사이의 차이를 계산한 값(loss function의 gradient로 mean squared error을 사용할 경우 actual residual이 된다)
- 앞서 구한 잔차를 새로운 종속변수로 하여 기본 학습기(Base learner)에 fitting한다.
- 즉, ${(x_{i}, r_{im})}^{n}_{i=1}$를 통해서 학습이 진행되며, $h_{m}$은 학습이 진행된 후 residual $r_{im}$에 대해서 예측하게 된 예측값이다.
- 상수 $\gamma_{m}$을 one dimensional optimization을 통해서 풀어낸다.$$ \gamma_{m} = argmin_{\gamma} \sum^{n}_{i=1} L(y_{i}, F_{m-1}(x_{i}) + \gamma h_{m}(x_{i})) $$
- 위의 결과를 바탕으로 모형을 업데이트한다.$$F_{m}(x) = F_{m-1}(x) + l \cdot \gamma_{m} \cdot h_{m}(x)$$
- 각 단계에서 pseudo-residual을 구한다 $$r_{im} = -\left [ \frac{\partial L(y_i, F(x_i))}{\partial F(x_i)} \right ]_{F(x)=F_{m-1}(x)} $$
- 최종 모형 $F_{M}(x)$를 도출한다.
GBM 예시
GBM에서 비롯된 모델들은 XGBoost, Light GBM(LGBM) 등이 있다.
- XGBoost
- LGBM
(추후 업로드 예정)
Reference
https://zephyrus1111.tistory.com/224#c1
20. Gradient Boosting 알고리즘에 대해서 알아보자 with Python
이번 포스팅에서는 Gradient Boosting의 개념과 알고리즘을 소개하며 이를 응용한 Gradient Tree Boosting의 개념과 알고리즘도 소개한다. 그리고 Gradient Tree Boosting 알고리즘을 파이썬으로 직접 구현하는
zephyrus1111.tistory.com
https://hyoeun-log.tistory.com/entry/ML-Gradient-Boosting-GBM
[ML] Gradient Boosting (GBM)
Boosting이란? 머신러닝 앙상블 기법 중 하나로, 약한 학습기를 결합하여 성능이 높아진 강한 학습기를 만드는 알고리즘이다. 오늘 다룰 Gradient Boosting은 이 Boosting 기법 중 하나이다. Gradient Boosting
hyoeun-log.tistory.com
https://3months.tistory.com/368
Gradient Boosting Algorithm의 직관적인 이해
Gradient Boosting Algorithm의 직관적인 이해 실패를 통해 성공을 발전시켜라. 낙담과 실패는 성공으로 가는 가장 확실한 두 개의 디딤돌이다. -데일 카네기 Gradient Boosting Algorithm (GBM)은 회귀분석 또는
3months.tistory.com
'머신러닝 > 알고리즘' 카테고리의 다른 글
| [머신러닝] LightGBM(LGBM) (1) | 2023.10.09 |
|---|---|
| [머신러닝] XGBoost (0) | 2023.08.23 |
| [머신러닝] Decison Tree (0) | 2023.07.27 |
| [머신러닝] Random Forest (0) | 2023.07.02 |
| [머신러닝] Ensemble Learning (0) | 2023.07.02 |



