
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- pca
- 앙상블 학습
- 최대사후확률
- 앙상블
- MLE
- Gradient boosting machine
- decision tree
- ensemble
- LDA
- Maximum A Posterior
- Gradient Boostnig
- Regression
- LGBM
- Gradient Boosting
- Machine Learning
- ML
- 차원 축소
- 머신러닝
- multivarite data
- 알고리즘
- multivarite method
- xgboost
- 트리분할
- dimension reduction
- feature extraction
- ensemble learning
- Gbm
- LIKELIHOOD
- classification
- 차원축소
- Today
- Total
코딩하는 눈송이
PCA(Principal Component Analysis) 본문
PCA란?
대표적인 Feature Extraction 기법 중 하나로, 기존의 데이터(d dimension)의 공분산 행렬에서 가장 큰 분산을 가지는 주성분(principal component)을 추출하여 새로운 좌표계로 변환 및 투영하는 방법이다.
분산이 가장 큰 주성분을 추출함을 통해 차원 축소로 인한 정보 손실(information loss)을 최소화한다. PCA는 데이터 압축, 노이즈 제거, 데이터 전처리 등에 사용할 수 있다.
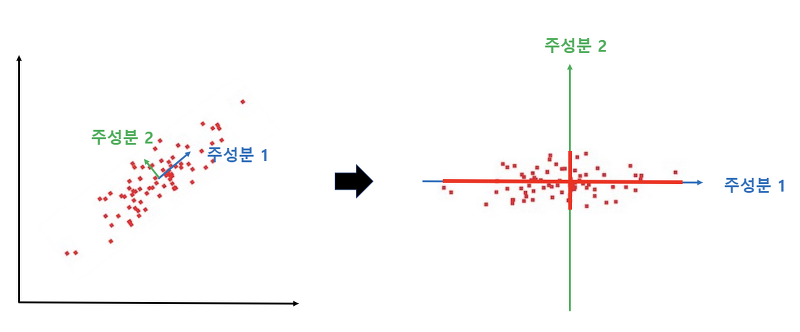
2차원 데이터에서의 예시
2차원의 데이터 x를 어느 한 direction(w)을 가지는 축에 투영한다고 해보자. 그렇다면 새로운 좌표 z는 다음과 같이 표현될 것이다.
$$z = w^{T}x$$
또한 위에서 설명한 것과 같이 가장 큰 분산을 가지는 축으로 투영을 해야 하므로 Var(z)를 최대화하는 direction w를 찾아보자.
$$ Var(z) =Var(w^{T}x) = E[(w^{T}x - w^{T}\mu)^{2}] $$
$$= E[(w^{T}x - w^{T}\mu)(w^{T}x - w^{T}\mu)]$$
$$= E[w^{T}(x-\mu)(x-\mu)^{T}w\ = w^{T}E[(x-\mu)(x-\mu)^{T}]w = w^{T}\Sigma w$$
여기서 $Cov(x) = E[(x-\mu)(x-\mu)^{T}] = \Sigma$이며 $w$는 unit vector이다.
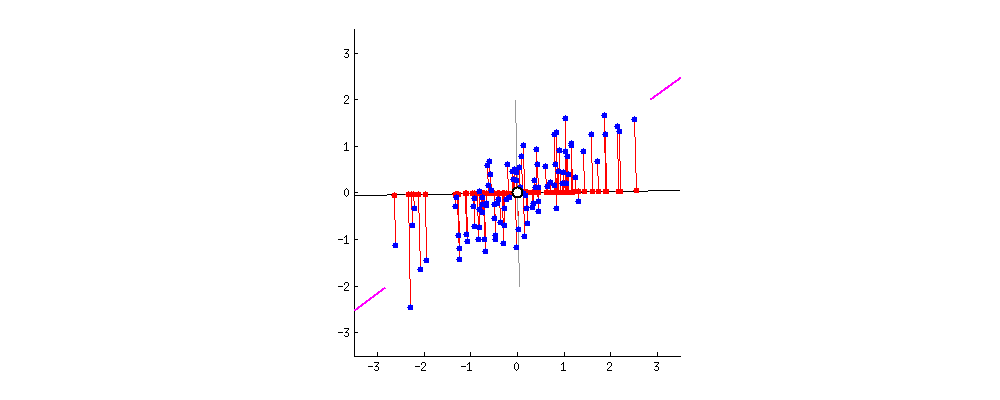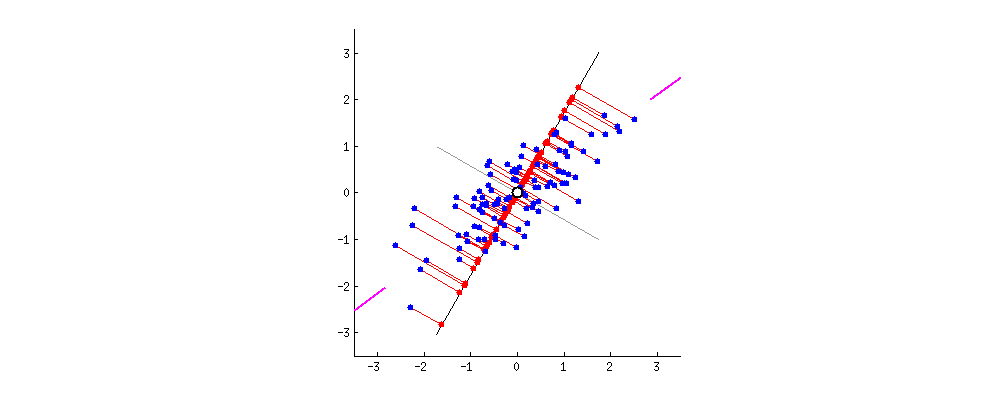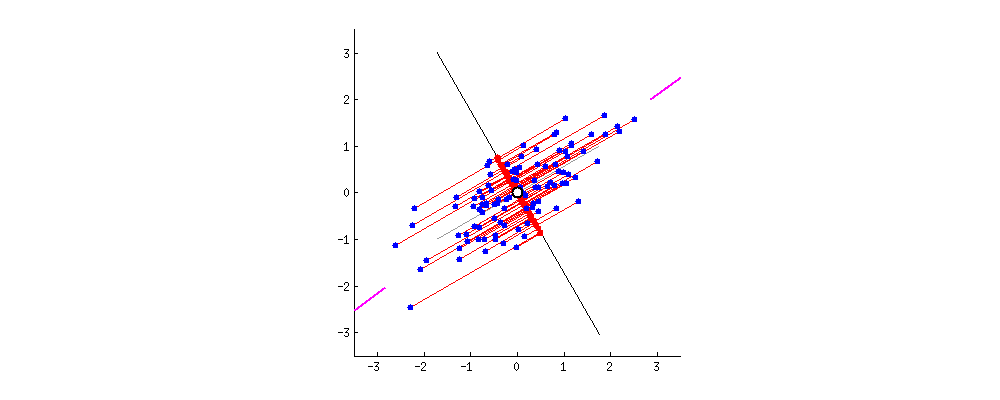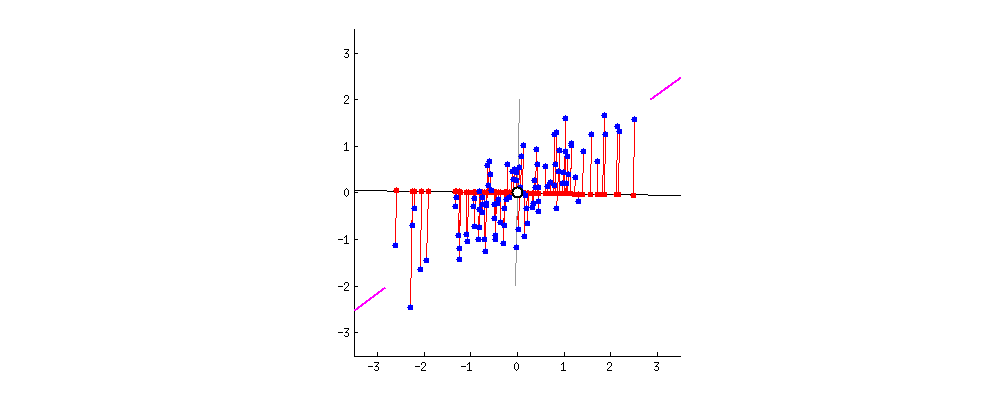
Projection할 축 찾기
그렇다면 투영된 값인 z의 분산을 maximize할 direction w를 구해 보자.
이 경우 라그랑주 function을 이용한다.
- 라그랑주 function이란? 제약 조건을 가진 최적화 문제에서 목적 함수인 f(x)를 최대화하거나 최소화하는 변수 x의 값을 찾는 것이 목적일 경우 사용된다
- i번째 제약 조건이 $g_{i}(x)$일 경우, 라그랑주 함수는 다음과 같이 나타내지며 목적 함수와 제약 조건들을 합한 형태로 표현된다$$L(x,\lambda) = f(x) + \lambda g_{i}(x) $$
- 이러한 형태로 변환한다면 제약 조건 없이 일반적인 최적화 기법을 사용하여 목적 함수를 최소화 혹은 최대화하는 변수 값을 찾을 수 있다
라그랑주 function을 이용하면
$$ L(w, \alpha) = w_{1}^{T}\Sigma w_{1} - \alpha(w_{1}^{T}w_{1} - 1) $$
라는 식이 나오며 이를 해석하자면
- $w_{1}^{T}\Sigma w_{1}$ : 주성분 벡터 w에 대한 목적 함수로, 데이터를 가장 잘 설명하는 주성분을 찾기 위해 해당 항을 maxmize하는 w를 찾으면 된다.
- $w_{1}^{T}w_{1} - 1$ : w의 제약 조건으로, w의 크기가 1이 되도록 제약을 가한다.
이 경우에서 라그랑주 함수를 편미분하게 되면 최적의 주성분 벡터 w를 구할 수 있게 된다.
w와 $\alpha$로 각기 편미분하는 경우. 모두 편미분 값이 0이 되어야지만 이 값이 최소, 혹은 최대가 되게 된다
$$ \frac{\sigma L}{\sigma w_{i}} = 0 \frac{\sigma L}{\sigma \alpha} = 0 $$
편미분한 결과를 정리해보면 정리해보면
$$ \Sigma w_{1} - \alpha w_{1} = 0 $$
결과적으로 $w_{i}$가 $\Sigma$의 eigen vector이며 $\alpha$가 eigen value일 경우 분산이 최대가 되는 축 w를 찾을 수 있게 된다(여기서 eigen value는 '설명력'이라고 한다)
- Second Principal Component : 두 번째 축 $w_{2}$에 대해서도 라그랑주 function을 통해 값을 구해보자 $$ L(w, \alpha, \beta) = w_{2}^{T}\Sigma w_{2}) - \alpha(w_{2}^{T}w_{2} - 1) - \beta(w_{2}^{T}w_{1} - 0) $$
- $\beta(w_{2}^{T}w_{1} - 0)$ : 이는 각 축 $w_{2}$와 $w_{1}$이 직교하기 때문에 둘을 내적하게 되면 0이 된다
- $w_{2}$로 편미분하게 되면 $\Sigma w_{2} = \alpha w_{2}$가 되어서 $w_{2}$ 역시 $\Sigma$의 eigen vector가 된다.
PCA의 결과
PCA의 최종 식을 쓰면 이렇게 된다
$$z = W^{T}(x - m) $$
W는 k X d 크기의 행렬이며 기존의 n X d 크기의 데이터 공간을 projection 시키는 주성분 벡터이며 $\Sigma$의 eigenvector이다
또한 m은 sample mean이며 m을 빼줌으로 인해서 PCA 이후의 데이터의 중심이 원점으로 이동하게 된다.
- Reconstructive Error : PCA를 통한 차원 축소를 감행하면서 일부의 데이터 정보 손실이 날 수 있다. PCA를 통해 차원 축소를 진행한 뒤 다시 원래의 차원으로 돌려놓을 시 발생하는 데이터 손실을 reconstructive error로 나타낼 수 있다.
- 원래 데이터($x$)와 차원 축소된 후 원래대로 돌려놓은 데이터($\hat{x}$) 사이의 유클리드 거리(Euclidean Distance)이다.$$ z W = W W^{T}(x - m) $$ $$ \hat{x} = z W + m $$
Projection할 축의 갯수를 구하는 방법
그렇다면 차원 축소를 감행할 때 몇차원(k)으로 축소할지 결정하는 기준이 어떻게 될까?
이는 앞서 설명한 설명력(eigen value) 값을 이용해서 구하면 된다.
각 주성분 벡터는 공분산의 eigen vector이었고, 각 eigen vector에 대한 $\alpha$ 값 즉, eigen value 값은 각 eigen vector이 데이터를 얼만큼 잘 설명하는지에 대한 설명력에 해당하며 각 성분의 중요도에 해당한다.
여기서 PoV(Proportion of Variance)라는 개념이 나온다.
- PoV란? 차원 축소 후 얼마나 많은 데이터 변동성(Variance)를 보존하는지를 나타내는 지표
이를 식으로 나타낸다면 다음과 같다
$$ \frac{\Lambda_{1} + \Lambda_{2} + ... + \Lambda_{k}}{\Lambda_{1} + \Lambda_{2} + \Lambda_{3} + ... + \Lambda_{d}} $$
쉽게 행렬로 정리해보자
W는 주성분 벡터 행렬로서 $w_{1}, w_{2}, ... ,w_{d}$로 이루어진 d X d 행렬이다
$W^{T}\Sigma W$를 통해 각 주성분 벡터에 대한 eigen value를 구해보면 다음과 같다.

위의 diagonal matrix의 각 $\sigma_{i}^{2}$ 값들은 각 주성분 벡터에 대한 eigen value에 해당하며 이는 PoV 식의 각 $\Lambda_{i}$에 해당한다.
($Var(z_{i}) = w_{i}^{T}\Sigma w_{i} = \alpha w_{i}^{T}w_{i} = \alpha$이며 $w_{i}^{T}\Sigma w_{i} = \alpha$ 즉 eigen value이다)
결론적으로 말하자면,
차원 축소하고자 하는 축의 갯수는 PoV가 0.9 이상이 될 때까지의 축 갯수대로 차원 축소를 진행한다.

위의 그래프에서 principal component의 갯수가 6개일 경우 PoV가 0.9 이상이 되기 시작하며, 이를 통해 차원 축소할 축의 갯수는 6개 혹은 그 이상이 적당하다는 판단이 가능하다.
Reference
https://ratsgo.github.io/machine%20learning/2017/04/24/PCA/
주성분분석(Principal Component Analysis) · ratsgo's blog
이번 글에서는 차원축소(dimensionality reduction)와 변수추출(feature extraction) 기법으로 널리 쓰이고 있는 주성분분석(Principal Component Analysis)에 대해 살펴보도록 하겠습니다. 이번 글은 고려대 강필성
ratsgo.github.io
https://seongyun-dev.tistory.com/4
[차원 축소] 주성분 분석 (PCA, Principal Component Analysis)
1. 주성분 분석 (PCA) 주성분 분석은 고차원의 데이터를 분산이 최대로 보존되는 저차원의 축 평면으로 투영시키는 대표적인 차원 축소 방법입니다. 이때 데이터를 투영시킬 수 있는 각 축의 단위
seongyun-dev.tistory.com
'선형대수' 카테고리의 다른 글
| Factor Analysis (1) | 2023.06.06 |
|---|---|
| LDA(Linear Discriminant Analysis) (0) | 2023.04.16 |
| 차원 축소 (0) | 2023.04.16 |
| Multivarite Methods(다변량 분석) (0) | 2023.04.15 |
| Regression (0) | 2023.02.13 |


