
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- multivarite method
- 최대사후확률
- Gbm
- multivarite data
- xgboost
- MLE
- Maximum A Posterior
- ensemble learning
- feature extraction
- ensemble
- LDA
- 머신러닝
- 차원축소
- Regression
- decision tree
- classification
- Gradient Boosting
- Gradient Boostnig
- Gradient boosting machine
- 앙상블 학습
- pca
- 차원 축소
- 앙상블
- dimension reduction
- LGBM
- LIKELIHOOD
- 알고리즘
- Machine Learning
- ML
- 트리분할
- Today
- Total
코딩하는 눈송이
Maximum Likelihood Estimation(MLE) 본문
Likelihood란?
Likelihood는 관측치가 어떤 특정한 분포(Distribution)에서 나왔을 가능성을 수치화한 것이다.
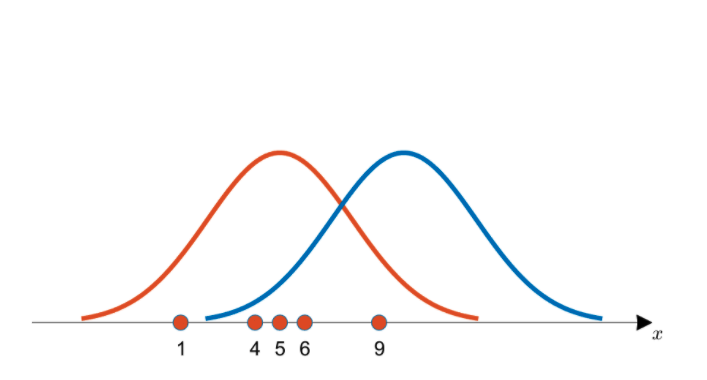
위의 그림에서 봤을 때 관측치는 파란색 분포보다 주황색 분포에서 나왔을 가능성이 더 높다.
이를 수학적인 방법으로 분포의 특성을 추정하는 방법이 Maximum Likelihood Estimation이다.
Maximum Likelihood Estimation(MLE)란?
수적인 데이터 밀도 추정 방법으로써 파라미터 $ \theta = (\theta_1, ... , \theta_m) $으로 구성된 어떤 확률밀도함수 $ P(x|\theta) $에서 관측된 표본 데이터 집합을 $ x = (x_1, ..., x_m) $이라 할 때, 이 표본들에서 파라미터 $ \theta = (\theta_1, ... , \theta_m) $를 추정하는 방법이다.
MLE의 수식은 다음과 같다
$$ L(\theta) = P(X|\theta) = P(x_{1}|\theta) \cdot P(x_{2}|\theta) \dotsm P(x_{n}|\theta) $$
MLE의 목적?
MLE의 목적은 데이터 분포를 맞추기 위한 최적의 방법을 찾는 것이다.
예를 들어
- Normal Distribution : 평균($\mu$)과 표준편차($\sigma$)를 가지는 연속 확률 분포
- Exponential Distribution : x가 0보다 클 시 $\lambda e^{-\lambda x}$ 확률을 가지는 연속 확률 분포
- Gamma Distribution : 양의 실수를 가지는 랜덤 변수에 대한 확률 분포
이렇게 데이터의 분포를 찾는 이유는 작업하기 쉬우며, 더 일반적(General)이기 때문이다.
데이터가 정규 분포(Normal Distribution)을 가진다고 가정해 보자.
그렇다면 이 데이터는
- 대부분의 관측치가 데이터의 평균값에 가깝다.
- 관측치가 평균을 중심으로 대칭이며 어느 한 곳으로 치우치는 경향이 적다.
하는 특징이 있는 데이터라는 사실을 알 수 있다.
- Likelihood는 실제에선 Probability와 큰 차이가 없게 사용되는 단어이지만 실제 likelihood는 관측치의 평균 혹은 표준 편차의 최적값을 찾는 상황에서 데이터를 어떤 분포에 부합하기 위한 방법으로 사용된다.
※ Likelihood Functions
Likelihood라는 것은 데이터를 얻은 분포에서 해당 분포로부터 관측치가 추출되었을 확률을 모두 곱해준 값을 likelihood function이라고 한다.
이는 모든 추출이 독립적이기 때문에 더하지 않고 곱하여 구해주는 것이다.
- Likelihood Function : $ l(\theta|X) = p(X|\theta) = \Pi_{t} p(x^t|\theta) $
- Log Likelihood Function : $ L(\theta|X) = log l(\theta|X) = \sum_{t} log p(x^t|\theta) $
여기서 MLE는 Likelihood function의 최대값을 찾아주는 방법이며 찾고자 하는 파라미터 $\theta$에 대해 편미분한 값이 0이 되는 지점을 찾아 likelihood 값을 최대화 시켜줄 수 있는 $\theta$를 찾을 수 있다.
※ 지도 학습에서의 적용
예를 들어 이진 분류(binary classification) 문제를 생각해보자.
입력 변수를 x, 두 개의 클래스(양성, 음성이라 해보자)로 표현되는 라벨을 y라고 하며 모델의 파라미터를 $\beta$라고 한다면
주어진 x에 대해 각 클래스에 속할 확률을 모델링하는 likelihood function은 다음과 같이 구성된다.
$$Likelihood(x,y|\beta) = P(y|x,\beta)$$
여기서
- x : 입력 변수(feature)을 의미하며, 주어지는 데이터 값이다.
- y : 이진 라벨을 의미하며, 주어지는 데이터 값이다.
- $\beta$ : 모델의 파라미터(가중치와 절편)을 의미한다.
전체 데이터에 대한 MLE 수식은 다음과 같이 표현된다.
$$Likelihood(X|\beta) = \Pi[P(y|x,\beta)]$$
여기서 $P(y|x,\beta)$는 로지스틱 함수인 시그모이드 함수로 표현되며
$$P(y=1|x,\beta) = \frac{1}{(1+e^{-\beta \cdot x})} = 1-P(y=0|x,\beta)$$
이렇게 likelihood 함수의 최대값을 찾는 것이 MLE의 목적이며 보통 로그를 취해 덧셈으로 치환하여 계산을 단순화하기 때문에
$$Log-Likelihood(X|\beta) = \sum[logP(y|x,\beta)]$$
여기서 log likelihood를 최대화시키는 $\beta$를 구하기 위해 최적화 알고리즘을 사용하게 된다.
이렇게 구한 파라미터를 활용해 로지스틱 회귀 모델을 학습시키고, 새로운 입력에 대한 클래스에 속할 확률을 구할 수 있게 된다.
참조
https://angeloyeo.github.io/2020/07/17/MLE.html
최대우도법(MLE) - 공돌이의 수학정리노트
angeloyeo.github.io
https://junha1125.tistory.com/24
최대 우도(가능도) 방법 (Maximum Likelihood Method)
공부를 위해 다음을 참고하였다. https://bit.ly/2ufTaQe - 확률분포가 어떤 분포인지에 따라서 최대 우도가 얼마인지 추정해본다. - 가장 단순한 베르누이 분포(이항 분포)일때, 이 블로그 내용을 추가
junha1125.tistory.com
'확률론' 카테고리의 다른 글
| Bias & Variance (0) | 2023.02.18 |
|---|---|
| Bayes' Estimator (0) | 2023.01.25 |
| Maximum A Posterior(MAP) (0) | 2023.01.24 |
